本系列的上一篇文章中,我们实战了proc_macro_workshop项目的debug题目。前两篇文章我们介绍的都是Rust过程宏中派生宏这个分支,这一次我们要介绍的是函数样式的过程宏。
好了,不废话了,准备好一台电脑,开始我们的第三个挑战任务seq
先是视频版本的教程,文字版本的在下面~
Rust过程宏开发实战系列(4-1) seq题目第1、2关【函数式过程宏+创建自定义语法树节点】
Rust过程宏开发实战系列(4-2) seq题目第3关【随机访问TokenStream内的TokenTree节点】
Rust过程宏开发实战系列(4-3) seq题目第4关【使用TokenStream匹配特定模式的代码片段】
Rust过程宏开发实战系列(4-4) seq题目第5、6关【使用syn::buffer模块进行TokenStream的遍历】
Rust过程宏开发实战系列(4-5) seq题目第7、8关【预读Token】
Rust过程宏开发实战系列(4-6) seq题目第9关【在宏中使用常量】
Rust过程宏开发实战系列(4-7) seq题目加餐【syn总结及syn包的其他使用方法】
文字版本
首先打开proc_macro_workshop项目的readme.md文件,看一下seq这个项目要实现什么样的功能。根据其中的描述,这个题目的最终目标是实现一个可以重复输出指定格式代码的宏,根据某个模板重复输出内容,并且在每次重复过程中修改某些带有序号的地方,这种模式我们在Rust自带的macro_rules!宏和quote包的quote!宏中都使用过,这一关我们也要实现一个类似的功能了。
与前两篇文章最大的不同点,有两个:
- 这次我们要写的是函数样式的过程宏,不再是派生样式的了
- 我们这次要打交道的主要是
TokenStream,而不是语法树节点了。- 我们要实现一种新的”自定义语言“,它扩展了Rust的标准语法。
- 因为本关中我们要处理的内容,并不是标准的Rust语法,所以没有办法解析成
syn包中提供的标准语法树节点。 - 所以,我们要自己定义一个【新的语法树节点】来表达我们的自定义语法结构
- 更严谨的来说,这一关是自定义语法和标准语法共存。因此我们既可以学到如何自定义一个全新的语法树节点,也可以学到如何在TokenStream的层面去操作标准Rust代码。
第一关
我们首先来看一下proc-macro-workshop对seq!这个过程宏的功能简介,说的是我们要实现一个形如下面这样的过程宏,这个过程宏可以帮助我们在代码的指定位置自动生成Cpu0、Cpu1、Cpu2…Cpu511这样的总计512个字段,每个字段标识符中都有一部分数字序号会发生改变:
1 | seq!(N in 0..512 { |
在上面这段示例中,我们可以看出:
seq!(......)这个格式是我们函数式过程宏的边界,就像派生式过程宏是对它下面的结构体生效一样,函数式过程宏是对过程宏名字后面的括号里面的内容做处理。N in 0..512 {.......}这个写法,包含了占位符声明(这里定义了N作为模板中每次变化的占位符)、重复开始的N值、重复结束的N值,以及要展开的代码模板 这四个部分。N in 0..512并不是标准的Rust语法,虽然我们可以写for N in 0..512{}这样的循环代码,但如果去掉了其中的for关键字,只留下N in 0..512这就不是标准的Rust语法了,所以你在syn包里面找不到它对应的语法树节点。当你完成这道题目以后,你完全可以自己定义出这样的语法,比如:N from 0 to 512 {....},只需要做很小的改动就可以实现N in 0..512 {.......}这个写法中,{.........}内部是一种标准Rust语法和自定义语法混合在一起的状态,因此,我们在后续几关的挑战中,一个核心的工作就是要从TokenStream中找出这些自定义的语法来做处理,而那些符合Rust语法的地方,我们尽可能复用syn包提供的功能。
划重点:学会如何处理这种混杂的代码,是这一道题目最有价值的地方。
了解了整体的功能之后,我们来看一下第一关的题目要求:
- 第一关要求我们解析
N in 0..512这个片段,识别出其中的syn::Ident,Token![in],syn::LitInt,Token![..],syn::LitInt这几个Token。 - 提示我们,这道题目,如果不使用
syn包也可以完成,但可能导致你需要写更多的代码,所以我们接下来的讲解还都是使用syn包的。 - 接下来,作者给出了两个参考资源的链接,分别是:
syn包中关于parsing功能的子模块说明:https://docs.rs/syn/1.0/syn/parse/index.html- 一个解析自定义语法树的示例项目:https://github.com/dtolnay/syn/tree/master/examples/lazy-static
上面两个参考资料大家一定要找时间自己看一下,不过可以先看完我的博客~好了,我们现在开始搭架子吧~~
首先打开seq/src/lib.rs,我们可以看到下面的框架, 其中的#[proc_macro]表示我们要编写的是一个【函数式】的过程宏,而下面函数定义中的seq指定了过程宏的名字,这一点和派生式过程宏是不一样的。派生式过程宏的名字不是由函数体定义的。
1 | use proc_macro::TokenStream; |
上面的结构先不动,我们先来定义一个新的struct用来表示我们的自定义语法树节点:
1 | struct SeqParser { |
我们来整体审视一下这个结构,它的前几个字段分别对应了几个具体的自定义语法元素,而最后一个字段,因为我们不确定里面有什么东西,所以使用TokenStream来记录所有的剩余代码片段,留作以后解析使用。这样的结构我们在syn包提供的标准Rust语法树节点中也遇到过,你能想起来吗?下面我留了几行空白,大家可以先想一下,然后往下滑动可以看到答案
- ===想想再往下翻===
- ===想想再往下翻===
- ===想想再往下翻===
- ===想想再往下翻===
- ===想想再往下翻===
- ===想想再往下翻===
在我们介绍Rust的属性元素对应的语法树节点时,我们提到过syn包提供的Attribute这个语法树节点(详见Builder题目的第七关),这个节点和我们这次的自定义节点非常相似,也是由固定的语法元素字段和不确定的TokenStream组成的,大家在读完本篇文章以后,可以再回过头来体会一下syn::Attribute这个语法树节点的设计思想。
定义好这个语法树节点以后,我们需要给它实现一个名为syn::parse::Parse的Trait,这个Trait中的parse方法读取TokenStream,看看其中的Token排列方式是否满足我们要求的语法模式,如果满足就将读取出的字段填充到自定义的语法树节点中。这个Trait的定义如下:
1 | impl syn::parse::Parse for SeqParser { |
可以发现,parse方法的入参是ParseStream类型,而不是我们之前说的TokenStream,那这个新的ParseStream是何方神圣呢?先打个预防针,从这一关开始到后续几关,我们会看到很多个新的数据类型,它们之间会有千丝万缕的联系,我们先给大家做一个整体总结,后面还会给大家详细介绍每一种类型,所以大家不要慌。我们会遇到的有关组件如下: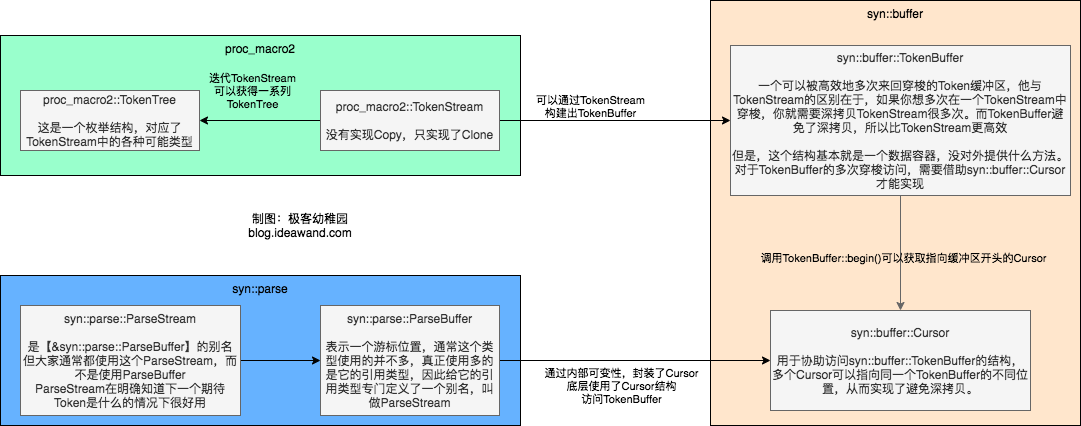
好了,禁止跑偏,我们赶快回归正题,回到ParseStream上面来,从上面的框图大概可以了解到,ParseStream是一种可以高效访问Token的数据结构,为我们提供了一些易于使用的方法。照葫芦画瓢,对照第一关题目要求中给出的官方文档链接以及lazy-static这个示例,我们可以用下面的代码来填充我们的自定义语法树节点:
1 | use syn::{self, braced}; |
可以看到,上面处理代码明显可以分为两种风格,对于普通的代码片段,我们只需要按照Token出现的顺序,依次调用parse()方法就好,但是当处理括号的时候,我们就要做一翻额外的工作。所以这里给一个重点提示:
重点&提示:在Rust提供的过程宏机制中,唯一没法自定义的Token就是括号,圆括号、方括号、花括必须成对出现,在输入的
TokenStream中就已经以括号为分割,将不同的代码片段划分为嵌套的Group,所以,在Rust的过程宏中,我们目前没有办法去自定义类似shell脚本中case语句那种以单个右括号表示一个分支的语法。如果大家有什么好的方法可以实现,请立即告诉我~
实现了自定义的Parse Trait以后,我们就可以把自定义的SeqParser类型作为一个新的语法树节点来使用了,修改我们的过程宏定义代码如下,看完下面这一行不知道大家会不会有一种恍然大悟的感觉:
1 |
|
这样,我们就通过了第一关的测试用例。
第二关
第二关的题目要求其实我们在第一关中就已经实现了。主要就是在说我们seq!(for N in 0..512{XXXXXX})这样的语法格式中,XXXXXX所在的位置,用户可以写任意的代码,所以我们没法直接将其解析为具体的语法树节点,需要先将其以TokenStream的形式存储下来。所以这一关直接通过~
第三关
第三关开始,我们要处理前两关中以TokenStream格式临时存储的用户代码,执行真正的展开操作了。
这一关,以及后面的几关中,我们都是要在TokenStream中进行穿梭,找到符合我们指定格式的片段,将其中的占位符替换为指定的格式。因此我们很有必要再来看一下TokenStream这个数据类型的内部构造。再强调一下,我们要研究的是proc_macro2包提供的TokenStream类型。
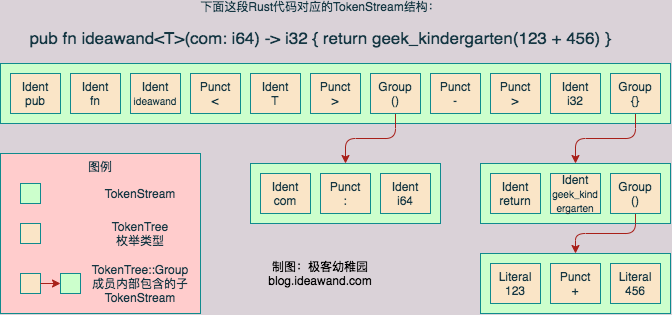
无论是通过Print大法观察TokenStream的形式,还是查看TokenStream的源代码,亦或翻阅proc_macro2的官方文档,我们都会发现和TokenStream形影不离的另外一个结构体TokenTree,查看源代码也可以看出,TokenStream的底层核心结构其实是一个Vec<TokenTree>,而这个TokenTree是一个枚举类型,包含4个成员,分别是:
Group非叶子节点,里面又包含子TokenStreamIdent叶子节点,表示一个标识符Punct叶子节点,表示一个标点符号(除了圆、方、花括号以外的其他不成对出现的标点符号,因为如果是括号的话,那么括号必须成对出现,而扩住的内容,就会以Group成员的形式出现)- 注意,尖括号是一个特例,
<T>不是一个Group,因为圆括号、方括号、花括号,必须成对出现,而尖括号所使用的<和>可以在大小比较、移位运算、返回值符号等多个地方,以不成对的形式出现,所以这里对待泛型参数时使用的尖括号并不是Group, - 我猜想是因为过程宏用到的Token解析比较简单,因为其他三种括号一定成对出现,所以确定一对括号出现的范围及其包含的内容,算法比较简单,而大于号和小于号要处理的case太多了,所以就没支持?
- 注意,尖括号是一个特例,
Literal叶子节点,表示一个字面量,可以是字符串字面量,也可以是数值型的字面量
经过上面的分析,我们可以有一个清晰的认识:Rust中所有的代码,在Token的层面上(也就是不考虑语法),其实只有3类:标识符、标点符号、字符串字面量,而Group呢,我个人没有把它算作一类,因为它只是前面3种基本类型的一个组合。而我们在看其他资料时(假设你了解macro_rules!宏),可能还会看到一些概念,比如stmt、expr、path等等,这些概念都是在语法分析后才能得到的,例如在语法层面上,我们把AA::BB的形式称为一个path;而如果从Token的层面来理解,它就是Ident(AA)、Punct(:)、Punct(:)、Ident(BB)组成的一个序列。这个概念我们在第一篇文章中已经介绍过了,如果生疏了可以再回看一下第一篇文章。
所以,看到这里,大家是不是会开始觉得,TokenStream这个名字起得有点骗人,它根本不是一个我们想象中的线性的Stream,它实质上是一棵多叉树!更严谨的来说,应该是:
- 只要我们不遇到各种各样的括号,那么
TokenStream的确是一个线性的Stream - 但是一旦遇到了圆括号、方括号、花括号中的任何一个,这个Stream就分叉了,就变成【树】了
是不是很坑?所以我们后面处理TokenStream的时候,其实都是在用遍历树的算法来搞,所以,这一关我们会涉及到很多的递归逻辑。好了,再上一张图,来直观感受一下TokenStream和TokenTree,可以看出来,如果横着看每一行,确实可以认为是一个”流“,但是加上纵向的内容,这就是一棵树。从图中也可以看到,TokenTree::Group类型本身记录了括号的不同类型。
上面说了这么多,我们现在开始真的进入第三关的题目,第三关的题目比较好理解,就是把用户代码重复指定次数,并在每次重复时,把其中的N替换为不同的数字。所以我们要做的就是遍历TokenStream,找到其中的N,然后将其进行替换。
在第一关给出的配图中,我们可以看到有多种手段可以处理这个原始的TokenStream,这些手段的使用方式以及执行效率各不相同,我们先介绍一种代码写起来比较简单直观,但是宏展开过程开销比较大的方法。
方法1:使用
TokenStream提供的迭代器,获得一个Vec<TokenTree>数组,因为转换成了数组,我们就可以通过下标来对各个TokenTree节点进行灵活的随机访问。
代码如下:
1 | impl SeqParser { |
仔细阅读一下上面的代码,注意其中的注释:
- 首先使用迭代器的collect方法,得到一个数组,这样我们就可以通过数组的下标来随机访问
TokenStream中的每一个TokenTree元素了- 吐槽一下,翻遍了整个
proc_macro2包,就没有任何的手段来随机访问TokenTree,只能通过迭代器顺序访问,所以只能通过先构造一个数组的方式,来实现随机访问。 - 我们上面的例子,对于随机访问的需求并不强烈,大家只是有个印象就行,等到需要后看、回溯等复杂匹配的时候,能想起来这个方法就行
- 吐槽一下,翻遍了整个
- 由于
TokenTree是个枚举,只有四种可能,所以就分别处理了。- 其中标点符号(Punct)和字面量(Literal)不需要处理,无脑透传就行
- 对于标识符(Ident),需要判断是否为要替换的标识符,并作出相应的处理
- 对于分组(Group),就需要递归处理了
- Group的
stream()方法可以帮助我们获得Group内部的TokenStream,但是这会导致标记Group区间的括号丢失掉,所以在递归调用结束以后,还需要手工把括号给补回来。g.delimiter()的作用就是获取这个group边界的括号类型
有了上面的展开函数以后,我们再来修改一下过程宏的入口函数,如下所示:
1 |
|
这段新增的代码非常简单,主要就是通过一个循环,将代码展开指定的次数即可。这样,我们已经可以通过第三关的测试用例了。
上面已经详细介绍了通过TokenStream和TokenTree来解析自定义语法的方法了,下面来说一下这种方法的缺点:TokenTree只实现了Clone,每一次遍历TokenStream得到TokenTree数组的时候,都是对当前节点及其树形结构下层节点的一次克隆操作,开销比较大,特别是在解析语法时,通常需要前看几个节点、递归内层结构等,如果某个语法规则匹配不上还要回退尝试其他语法规则,这样就导致了效率低下。在后面的关卡中会为大家介绍其他的方法。
综上所述,在访问TokenStream的节点的时候,开销比较大。如果我们不需要在TokenStream中来回穿梭,不需要前前后后访问每一个Token的话,用TokenStream也不是不行,它用起来是比较简便的。
第四关
在第三关中,我们实现了对标识符N替换为对应数字的功能,但是这个功能基本上没有太大的用处。因为我们在使用这个过程宏的时候,通常是希望产生一个标识符的,也就是以字母开头,以可变数字N结尾的一组标识符,而我们上一关中把N替换为一个数字,实际上是产生了一个数值类型的字面量,那么这一关的内容就是要解决这个问题:我们在代码中搜索xxx#N这种形式,其中xxx是一个标识符前缀,#N代表着要在xxx后面追加一个动态变化的数字后缀。只有找到满足这种模式的代码片段时,我们才能进行过程宏的替换。
所以,这一关的重点其实就是需要向后预读两个TokenTree元素。
这里需要注意一个问题:
- 对于
xxx#N这样一个代码片段,我们得到的TokenStream实际上是3个:一个标识符xxx、一个标点符号#、一个标识符N - 对于
xxx # N、xxx #N、xxx# N这几种写法,我们得到的TokenStream都由3个元素组成 - 所以,我们除了要判断这三个元素的出现顺序以外,还要根据他们的Span的信息,来检验他们在源代码中是不是紧密连在一起的。
- 为了在代码中能够访问一个Token的位置信息,需要给
proc-macro2这个包开启span-locations这个特性
另外,很重要的一点,虽然我们要支持xxx#N这种写法,第三关的N的写法也还要支持。这就涉及到匹配优先级的问题,不过这个还是很好解决的,优先匹配长的规则就好。
下面我们来看一下代码,注意其中的注释:
1 | impl SeqParser { |
经过上面的代码修改,我们就已经可以成功通过第四关了。回忆前文的示意图,解析自定义语法有几种不同的方式,上面的解法实际还是基于先将TokenStream转换为TokenTree数组的方式来实现随机访问,也就是上面图中绿色背景所包含的内容,这些都是由proc_macro2这个包提供的数据结构和工具。我们将在下一关中来给大家讲解一下另一种解析语法树的方式,也就是上面图中黄色背景所包含的内容,这部分数据结构和工具是由syn包提供的。
第五关
这一关的题目要求是说,我们要在seq!宏用户书写的代码块中,找到#(xxxxxxxxx)*这种特定的模式,只有在这种模式内部,也就是xxxxxxxx对应的位置是需要重复的,而#(xxxxxxxxx)*模式之外的代码不能重复。
所以这里我们还是要做一个和第四关差不多的模式匹配过程,不过这一次,我们使用一套全新的数据结构和工具:
- 我们要将
proc_macro2::TokenStream通过syn::buffer::TokenBuffer::new2()转换为一个syn::buffer::TokenBuffer类型的对象 - 调用
syn::buffer::TokenBuffer的begin()方法,可以得到一个指向syn::buffer::TokenBuffer开头的Cursor对象 Cursor对象提供了一系列方法,可以解析TokenBuffer中的Token,如果解析成功,则返回解析的元素以及一个【新的】Cursor对象,为了便于理解,可以看下面的图示:
1 | fn blog(ideawand: u8, geek_kindergarten: u8) {} |
- 假设
TokenBuffer中存储了fn blog(ideawand: u8, geek_kindergarten: u8) {}这一行代码对应的Token,则调用TokenBuffer的begin()方法,可以获得上述c1这个Cursor,这个Cursor指向了TokenBuffer的开头。 - 调用
c1.ident()方法,尝试将c1所指向的位置解析为一个标识符,如果成功,则会返回两个变量,一个是我们读取到的标识符,在这里也就是fn, 另一个是向后移动了一个Token的另一个新Cursor,也就是c2。 - 我们可以继续调用c2的
ident()方法,得到blog这个标识符,以及另一个新的Cursor,也就是c3 - 对于c3,因为指向了一个括号,因此需要调用
c3.group()这个方法,这个方法会返回两个新的Cursor,c4和c5,其c4指向这个group内部的第一个Token,而c5指向跨过这个Group以后的第一个Token - 如果此时要继续解析圆括号中的内容,那么就在c4上继续调用对应的方法,顺着c4往下走,c4走到图中e指向的位置时,便是走到了尽头,如果想跳过圆括号向后解析,则应该在c5上继续调用对应的方法,顺着c5走下去
- 由于每一次都是返回一个新的
Cursor,所以在需要回溯的地方只需要缓存一下对应的Cursor就可以了,比如在解析到c3的时候才发现情况不对,那么只需要丢掉c3,从c1或者c2继续往下解析就可以。
好了,有了这么多的铺垫知识,我们可以开始写这一关的代码了,我们来写一个新的函数,用来从代码中识别出#(xxxxxxxxx)*这个模式,如果识别出来了,则调用我们在上一关中已经写好的expand函数。同时,我们需要额外返回一个布尔型的标记,用于标记我们是否成功进行了展开,因为要考虑前面几关的测试用例,当我们扫描完整个代码,发现并没有找到这样的模式时,我们还要用上一关实现的expand函数,对整体代码进行一次展开:
1 | fn find_block_to_expand_and_do_expand(&self, c: syn::buffer::Cursor) -> (proc_macro2::TokenStream, bool) { |
然后再修改一下过程宏的入口:
1 |
|
好了,通过上述的修改,通过第五关就没问题了。
第七关
这一关太简单了,唯一的一个知识点就是介绍一下syn::parse::ParseStream类型提供的peek()方法吧,它可以在不消耗ParseStream的情况下,后看一个Token是什么,类似的方法还有peek2()和peek3(),顾名思义,就是后看第二个或者第三个Token。
1 | fn parse(input: syn::parse::ParseStream) -> syn::Result<Self> { |
第八关
这一关就是校验一下产生的错误提示信息是否正确。因为我们前面在拼接生成XXX#N这种模式的标识符的过程中,已经把新生成的标识符的span信息处理好了,所以这里可以直接通过。
第九关
这一关同样不用修改任何代码,出题者只是希望通过这个测试用例,来给我们演示一种Trick,展示了我们编写的过程宏如何与macro_rules!定义的普通宏交互配合。
测试用例中想表达的意思就是,我们不能在过程宏使用其他代码中定义的const变量作为过程宏的入参,也就是比如我们在这道题目中实现的seq!,需要指定一个重复次数N,这个N不能是其他地方定义的常量。究其根本原因,还是我们已经在前面的文章中提到过很多次的问题:过程宏展开的时候还没有经过名称解析。
然后这一关的测试用例,提出了另一种方法,就是通过macro_rules!的方式,来绕过这个限制,它的核心思想是这样的:
- 你想定义一个const的变量,其实就是你想在一个地方定义一个值,然后在多个地方引用这个值。
- 我可以定义一个宏,这个宏可以展开成一个常量的字面量,比如一个数字或者一个字符串
- 相比于原来在各个地方直接引用const类型的变量,现在改成在需要的地方做一下宏展开
- 最终效果都是一致的,无论是用const,还是用宏,如果我要修改这个常量,只要在一个地方修改就可以了
当然,在本关的测试用中,出题者还是给我们演示了一下宏和const组合在一起使用的方法,即通过宏来定义一个const。
总结
seq!宏这道题目设涉及了syn包、proc_macro2包的很多使用技巧,也引入了很多新的数据类型。在文章开头我们给出了一张图片,当时大家可能看的比较懵,现在我们再拿出这张图来看一下,总结归纳一下这些数据类型的用法:
首先是syn::parse模块提供的数据类型:
- 左下角的
ParseStream是我们在第一关中就遇到的类型,它实际是左下角ParseBuffer类型引用的一个别名 - 无论是
ParseStream还是ParseBuffer,这两个类型不能由我们自己来创建,只能通过syn包内部生成并通过某些接口提供给我们来使用 ParseStream提供的是高层的封装,提供了很多高层次的API,详细内容请大家参阅syn的文档
然后看syn::buffer模块提供的数据类型:
TokenBuffer是一个Token的容器,没有提供什么公开的方法,不能直接使用- 通过
Cursor类型的对象来访问TokenBuffer中的Token syn::buffer的底层使用了unsafe的方式,避免了遍历过程中的Copy,效率比较高- 上面提到的
syn::parse模块也是基于syn::buffer实现的
最后看一下proc_macro2模块提供的数据类型:
TokenStream是由TokenTree组成的树形结构,是最原生态的一种数据结构- 通过遍历
TokenStream可以得到TokenTree数组,通过下标来随意地访问其中的内容 - 不支持Copy,每次Clone会复制全部子节点,代价比较大
